Starting the San Francisco Cognitive Science Reading Group
February 11, 2023 | Comments
I really enjoyed spending some time last year learning about cognition, and I didn’t want it to end there. Plus as we (kinda, sorta) come out of COVID, I wanted to start meeting other human beings - maybe even ones I didn’t already know.
After observing that Meetup groups seem to be a wasteland - huge member numbers but no activity in most of them - I’ve set up the San Francisco Cognitive Science Reading Group. We have a first event in early March, at which we’ll discuss Being You, by Anil Seth. I’m still working on a venue - it’ll be an in-person event, though if we can support remote attendees we will do so.
Register! Like and subscribe! Join us!
2022 Redux
January 03, 2023 | CommentsI wanted to write something about 2022, to get it out of my head before 2023 rolls over it. An odd year - disjointed, mostly by choice, and feels better in retrospect than it did at the time. I remember having a strong sensation throughout it that it never hit a consistent rhythm.

Work-related:
- I’m still working in Google Research - it’ll be 5 years in my current role in May. My manager is about to become my All Time Longest Ever Boss - ssh don’t tell him, it’s going to be a surprise. We published a white paper and blog post about Private Compute Core, which might be the most important thing I’ve done? It certainly gave me a strong sense of mission; I spent 3 years setting up this and Android System Intelligence, before moving on to other things: audio and ambient sensing. I am grateful to be working in AI right now.
- I took a 3 month break from work. It was great. I wrote all about it here.
- I spent a few months volunteering for Rewiring America, helping with their Mayors for Electrification program. They’re an excellent organization and I love their work, their ethos and their people; but I didn’t feel I was actually getting much of any use done, or that I had a surfeit of time to throw into it.
- I’m still doing advisory work for Small Robot Company. They’re doing technically difficult work to solve real problems in the real world, and hit some great milestones this year.
Health:
- Overall good - I exercised on 282 days, and my resting heart rate, VO2, etc are all good (but I’d like my VO2 to be excellent).
- Highlight: thanks to the purchase of a Yuba Boda Boda e-bike last year, I beat the cycling goal I’d set myself (~3200km vs 3000km goal for the year I think - grrr Strava for not allowing a historical view of goals). E-bikes are enormously fun, mine has quickly become my main mode of transport. When they break they’re less fun. One lesson from this year: buy a proper e-bike chain!
- Midlight: I didn’t quite manage to hit my running goal of 750km (I think I made it to 620km), but I was plagued by a hip injury that I’ve had for a couple of years and only ended up fixing this year thanks to physical therapy, so don’t feel too bad about that. I’ve started doing longer runs (a 5.5km loop up and down Twin Peaks and a longer downhill 8.5km to work), and my times got better towards the end of the year, approaching what they were in my 30s.
- Lowlight: I only did 75 hours of karate (vs a goal of 150). Partly because I was away, partly a series of injuries (toe, wrist, hip, chest…). I do feel like my sparring has become much more controlled this year. I’m planning to focus more on this in 2023, it could be an exciting year.
- Notable mentions: I’ve started to spend more time walking in the countryside. I did a lot of this in Italy and back in the UK, but I’ve also gotten into the habit of taking the odd day off work, driving up to Marin or Point Reyes, and just having a wander.
- Being Near That Age, I had my first routine colonoscopy - an introduction to the indignities of your twilight years, I guess. The prep was less pleasant than the actual event, which was under a general anaesthesia. I hadn’t had that since I was 17 maybe? I started counting backwards from 10, the crew laughed and said “we don’t do that any more but you can if you like”, then a vaguely metallic taste in my mouth and I was gone.

Books; I read 37 books in total this year, thanks in part due to time off, in part due to deliberate effort. I probably won’t read as much this year. Some of the best ones, a sentence of pith for each:
- Being A Human by Charles Foster (sequel to Being a Beast, which I loved): tl;dr understand the human condition by pretending to be Neolithic
- The Mortdecai Trilogy by Kyril Bonfiglioli: a friend recommended this to me 10 years ago and I kick myself for not having listened to them. Laugh-out-loud upper-middle class English shenanigans.
- How to Take Smart Notes by Sönke Ahrens, after which I am Zettlekastening
- Hand, Head, Heart by David Goodhart : tl;dr we overprivilege cognitive ability and jobs arising from it, relative to those in the manufacturing or caring professions. Goodhart also wrote The Road To Somewhere, which really helped explain the new cross-society divisions behind Brexit.
- Lanny, by Max Porter, author of the incredible Grief Is The Thing With Feathers. Terrifying medieval England-spirit does terrifying things in English village, terrifyingly.
- Metazoa, by Peter Godfrey-Smith; tl;dr how far down the tree of life does consciousness emerge? Seems like the closer we look, the further back it goes.
- Scientific Freedom: The Elixir of Civilisation, by Donald Braben; tl;dr what’s the best way to fund foundational research? Cast the net wide, fund exceptional people without conditions, don’t have outcome-related goals. I read this, and others, to think a bit more carefully about my working life.
- Slaughterhouse 5, Kurt Vonnegut. Just sad I hadn’t read it already. So it goes.
- The Diamond Age by Neal Stephenson. Read on a whim after a tweet from Emad Mostaque saying “who wants to help build the book from this?”. Beautiful novel - nanotechnology, future Victorian nostalgia, centered around a magic book designed to teach a young girl how to be subversive.
- The Prince of the Marshes and The Marches, by Rory Stewart. I became a big fan of his in the last few years after reading The Places In Between, about his walk across Afghanistan post-9/11. The first of these concerns his time as a regional governor in post-war Iraq, the second his relationship with his father.
- The Self-Assembling Brain, by Peter Robin Hiesinger; AKA So You Thought Understanding The Brain Was Hard, Let Me Make It A Thousand Times Harder For You. Basically: brains are grown not laid out, and the process of growth - unfolding sequences, Komolgorov-style - is an efficient, wickedly hard to understand primitive for brain understanding.
- What is Life, by Addy Pross; tl;dr where does life come from? Self-replication in an environment finite enough that you’re competing for resources, leading to specialization, competition, and (once life starts harvesting energy) take-off. Really wonderful book.
Other stuff:
- I went back to the UK for my cousin’s 50th birthday in November. It had been a decade since I was in a pub with 30+ good friends, and it left me feeling nostalgic for those days: we’ve made some good friends in the US, but there’s something about a social circle which mostly predates adulthood… having one such friend visit for 10 days was also really quite wonderful, I may never get that length of contiguous time with them again.
- I saw a lot of my dad this year - that November trip, a month working from the UK early in the year, a week in Italy, a trip for him to SF, and some sundry days passing through on work trips.
- We tried to start some construction work (a basement remodel with a side order of structural, plus some solar panels), and I have now been initiated into the ways of local government. Obscure, opaque, slow moving. I haven’t gone libertarian, but am definitely mentally looking over my spectacles when someone suggests more services be government-run.
- I’ve joined the School Site Council for my daughter’s elementary school, to start getting a feel for that side of local politics.
- I started enjoying a couple of new podcasts: The Rest is Politics (Alastair Campbell and Rory Stewart giving insider views on UK and world politics) and Brain Inspired (excellent interviews with neuroscientists and AI types, with a good Discord for supporters).
- Courtesy of James, I found Buck 65’s substack and bounced from there to a load of his music, which I’ve been loving - in particular Laundromat Boogie (a concept album about doing laundry), and two collaborations: The Last Dig and Bike for Three
92 Days Off
October 16, 2022 | CommentsI spent 3 months over the summer on a break from work (if you’re feeling pretentious, feel free to call it a sabbatical) mostly to keep a promise I made to myself a decade ago: when I was interviewing at Google my recruiter had warned me that without a degree (which I lacked) I might succeed at interview and fall at the final hurdle. So I booked onto a MSc at Sussex, absolutely loved it, and ended it swearing I’d take a year off every ten thereon to focus on lifelong learning. Then I blinked, ten years had passed, and I found myself thinking awkwardly about how to keep both this promise and my job. I’m exceptionally fortunate to have an employer with a generous view of taking time out, so that’s what I did.

Common advice online was to start any break with a complete change of scene and habits, so I spent the first month in Tuscany, tucked away in the countryside near Figline Valdarno (between Florence and Siena) with a pile of books, some walking boots and my running shoes. I slept voraciously, read indulgently, and hiked around the local countryside until I was sick of the sight of terracotta and lush greenery. Towards the end my dad came out to visit and we continued in this vein together.

Then it was back to the Bay Area, where to scratch that educational itch I’d signed up for a course at Berkeley University as part of their summer program, Computational Models of Cognition. I figured that being in a university environment would be stimulating, I’d meet a load of like-minded people, the topic would give me an opportunity to look at biological aspects of intelligence (the day job focusing on silicon), and going a bit deeper on machine learning theory couldn’t hurt.
In practice my experiences were mixed. Where I’d expected to be one of many mature students along for the ride (Bay Area! Cognition! AI! 2022!), I seemed to be the only attendee over the age of 27. This was OK and everyone was very sweet, but I’d met That Guy during my brief undergraduate time at Reading, and been That Guy once already at Sussex. On the ML theory side of things, we didn’t go as deep as I’d hoped - building a simple feedforward network from scratch but not much more. The biological side was much more interesting, forcing me to revisit GCSE chemistry as we looked into exactly how synapses fire and impressing upon me the overwhelming complexity of the brain as we looked at key circuits in the hippocampus.
To pad this out, I took the excellent Brain Inspired Neuro AI course, an online effort from Paul Middlebrooks who runs a podcast of the same name. This course examined the same subjects, a little more broadly and superficially than the Berkeley course, and very capably. I particularly liked how Paul had extended the prerecorded lectures with regular calls for questions which he then answered in follow-up videos; and after subscribing to his Patreon, I’ve been enjoying the Discord-based community around the podcast.
Lots of real life happened during this time too: visits from my dad and an old friend from Brighton, both of which triggered some explorations of California countryside; a bout of COVID which passed through me and Kate, but (thanks perhaps to diligent masking and extreme ventilation) avoided our daughter B; we lost a much-loved cat; and B and I started learning to roller-skate in GGP. I also resurrected my Birdweather station - for reasons work-related and personal, ambient birdsong tracking has become interesting to me - and indulged an interest in bee navigation which I wrote about previously.
I read a lot. Here are some books I particularly enjoyed during this time; all are excellent and recommended.
- Don’t Point That Thing at Me, by Kyril Bonfiglioli - laugh-out-loud 70s cloak-and-dagger novel, starring an alcoholic middle-aged art historian.
- Lanny, by Max Porter - failing marriages, ancient spirits and the abduction of a child from an English village. Beautifully written from the author of the incredible Grief Is The Thing With Feathers.
- The self-assembling brain, Peter Robin Hiesinger - how do brains develop? Our models are static but biological systems grow, and the mechanism of their unfolding growth seem important to the end-results (perhaps but perhaps not essentially) and their efficient genetic coding (definitely).
- Seeing like a state, by James C Scott - the need for society to be legible to a state apparatus leads to an imposition of top-down order; the models needed are wrong, even if some are useful, and forcing your reality to conform to a model doesn’t work. Hard not to see the connections between the emancipatory nature of high modernism and modern tech culture - “we’re building better worlds”…
- Build, by Tony Fadell - on the topic of building software/hardware products, and excellent. I started finding this a bit trite, but as I worked through it I loved it more and more. Chapter 6 in particular was an astonishing record of what it’s like to actually sell to Big Tech.
- The Prince Of The Marshes, Rory Stewart, an account of the author’s time as an acting governor in post-war Iraq, with a theme of the importance of devolution throughout. I became a bit of a Rory Stewart fanboy after reading The Places In Between (on James’ recommendation) and have really been enjoying his podcast with Alastair Campbell, The Rest is Politics
- Head, hand, heart by David Goodhart, follow-up to the excellent Road To Somewhere, about the over-privileging of cognitive ability (relative to manual and caring skills) and how it’s damaged society.
- The Upswing, Robert Puttnam, a follow-up to Bowling Alone which seems to throw its predecessor under the bus in looking back further and plotting many aspects of American society on an inverted U-curve during the 20th century… with a common sentiment that while things are bad, but we’ve been here before and prevailed. Exhaustive, fascinating, ultimately optimistic.
- What is life, Addy Pross: how does chemistry become biology? A similar question to Gödel Escher Bach I guess, but lays out evolutionary principles: replication of simple molecules in a finite environment leads to competition and thus efficiency; then energy-harvesting arrives, and you have life.
Be kind, Bee mind
August 11, 2022 | Comments(sorry)
I’ve been on a break from work for the last few months, and one of the things I’ve been doing is learning more about the brain: by taking Computational Models of Cognition as part of Berkeley University’s Summer Sessions, doing the (excellent) Brain Inspired Neuro-AI course, and of course listening and reading around the topic. I’ll write more about this another time, maybe.
I was charmed by this interview on the Brain Inspired podcast with Mandyam Srinivasan. His career has been spent researching cognition in bees, and his lab has uncovered a ton of interesting properties, in particular how bees use optical flow for navigation, odometry and more. They’ve also applied these principles to drone flight - you can see some examples of how here.
Some of the mechanisms they discovered are surprisingly simple; for instance, they noticed that when bees entered the lab through a gap (like a doorway), they tended to fly through the center of the gap. So they set up experiments where bees flew down striped tunnels, while they moved the stripes on one side, and established that the bess were tracking the speed of motion of their field of view through each eye, and trying to keep this constant. Bees use a similar trick when landing: keeping their speed, measured visually, at a constant rate throughout. As they get nearer to the landing surface, they naturally slow down. Their odometry also turns out to be visual.
The algorithm for centering flight through a space is really simple:
- Convert what you see to a binary black-and-white image.
- Spatially low-pass filter (i.e.blur) it, turning the abrupt edges in the image into ramps of constant slope.
- Derive speed by measuring the rate of change at these ramps. If you just look at the edge of your image, you’ll see it pulses over time: the amplitude of these pulses is proportional to the rate of change of the image and thus its speed.
- Ensure the speed is positive regardless of direction of movement.
Srinivasan did this using two cameras, I think (and his robots have two cameras pointing slightly obliquely). I tried using a single camera and looking at the edges.
It seems to work well on some test footage. Here’s a video I shot on a pathway in Sonoma, and here’s the resulting analysis which shows the shifts I was making between left and right during that walk, quite clearly:
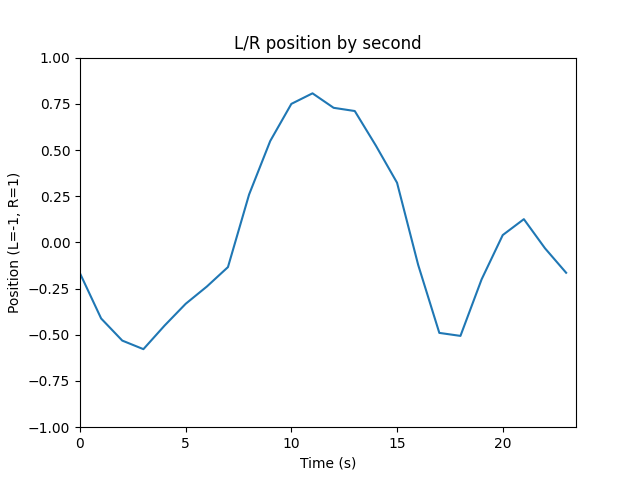
Things I’m wondering about now:
- Making it work for robots: specifically, can I apply this same mechanism to make a Donkey car follow a track? (I’ve tried briefly, no luck so far)
- Do humans use these kinds of methods, when they’re operating habitually and not consciously attending to their environment? Is this one of a bag of tricks that makes up our cognition?
- What’s actually happening in the bee brain? Having just spent a bit of time learning (superficially) about the structure of the human brain, I’m wondering how bees compare. Bees have just a million neurons versus our 86 billion. It should be easier to analyze something 1/86000 of the size of the human brain, no? (fx: c elegans giggling)
Srinivasan’s work is fascinating by the way: I loved how his lab has managed to do years of worthwhile animal experiments with little or no harm to the animals (because bees are tempted in from outside naturally, in exchange for sugar water, and are free to go).
They’ve observed surprisingly intelligent bee behavior: for instance, if a bee is doing a waggle-dance near a hive to indicate food at a certain location, and another bee has been to that location and experienced harm, the latter will attempt to frustrate the former’s waggle-dance by head-butting it. That seem very prosocial for an animal one might assume to be a bundle of simple hardwired reactions! After reading Peter Godfrey-Smith’s Metazoa earlier this year, has me rethinking where consciousness and suffering begin in the tree of life.
I’ve put the source code for my version here.
Startup chime
July 20, 2022 | CommentsI found this dusty old box in a cupboard, dug out a few old cables and plugged it in. I wonder if it works?